Kafka
背景优劣
Kafka技术产生的背景。
优势:
劣势:
安装部署
准备磁盘
- 磁盘冗余阵列:一般至少一个副本,做raid5即可
- 磁盘分区格式:文件系统建议用 xfs (kakfa love xfs),服务器默认 ext4,如果重新格式化,请修改 /etc/fstab 并修改文件系统类型
- 禁用交换分区:
sudo swapoff -a
安装软件
1.Download the code
> tar -xzf kafka_2.12-2.4.0.tgz
> cd kafka_2.12-2.4.0
2.Start the server
> bin/zookeeper-server-start.sh config/zookeeper.properties
> bin/kafka-server-start.sh config/server.properties
3.Create a topic
> bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
> bin/kafka-topics.sh --list --bootstrap-server localhost:9092
4.Send some messages
启动脚本
KAFKA_HEAP_OPTS 变量设置 JVM HEAP 内存。Kafka 启动和停止的时间,视数据量而定,查看日志或者在 kafka-manager 后台查看实时流量
Kafka 命令
启动zookeeper
nohup /usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties >> /data/logszookeeper/zookeeper.log 2>&1 &
启动kafka
nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server-1.properties >> /data/logskafka/kafka-server-1.log 2>&1 &
nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server-2.properties >> /data/logskafka/kafka-server-2.log 2>&1 &
nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server-3.properties >> /data/logskafka/kafka-server-3.log 2>&1 &
tail -fn 3 /data/logskafka/kafka-server-*.log
创建消息主题
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test1
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 10 --topic test
查询主题列表
kafka-topics.sh --list --zookeeper localhost:2181
查看特定主题
kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
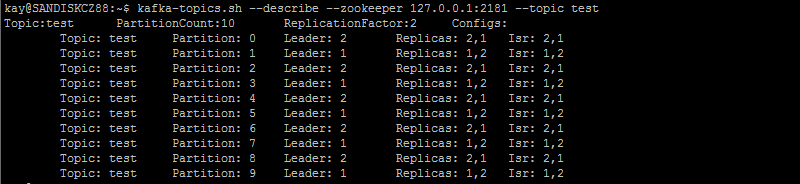
- leader 负责给定分区的所有读取和写入的节点。每个节点将成为随机选择的分区部分的领导者。
- replicas 复制此分区日志的节点列表,无论它们是否为领导者,或者即使它们当前处于活动状态。
- isr “同步”复制品的集合。这是副本列表的子集,该列表当前处于活跃状态并且已经被领导者捕获。
生产者与消费者
kafka-console-producer.sh --broker-list localhost:9092 --topic test
kafka-console-consumer.sh --from-beginning --bootstrap-server localhost:9091 --consumer-property group.id=mygroup --topic test
Kafka 配置
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs-1
---
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-2
---
config/server-3.properties:
broker.id=3
listeners=PLAINTEXT://:9095
log.dir=/tmp/kafka-logs-3
配置实例
broker.id=1
listeners=PLAINTEXT://192.168.1.104:9091
log.dirs=/tmp/kafka-logs-1
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
核心配置
broker.id
每个节点一个id,不允许重复,建议把它们设置成与机器名具有相关性的整数,这样在进行维护时,将ID号映射到机器名就没那么麻烦了;
zookeeper.connect
Zookeeper地址,该配置参数是用冒号分隔的一组hostname:port/path列表,必须指定/path路径,作为Kafka集群的chroot环境; 在Kafka集群里使用chroot路径是一种最佳实践。Zookeeper群组可以共享给其他应用程序,即使还有其他Kafka集群存在,也不会产生冲突。 最好是在配置文件里指定一组Zookeeper服务器,用分号把它们隔开,一旦有一个Zookeeper服务器宕机,broker可以连接到Zookeeper群组的另一个节点上。
default.replication.factor
副本数,默认为 1,即没有副本,按需配置,建议:2
auto.create.topics.enable
是否自动创建Topic,上报即创建,按需打开
delete.topic.enable=true
是否支持删除Topic,建议:true
log.retention.hours
数据保存多长时间,单位小时,建议:720
port
默认9092端口
log.dirs
Kafka把所有消息都保存在磁盘上,存放这些日志片段的目录是通过log.dirs指定的。它是一组用逗号分隔的本地文件系统路径。如果指定了多个路径,那么broker会根据“最少使用”原则,把同一个分区的日志片段保存到同一个路径下。要注意,broker会往拥有最少数目分区的路径新增分区,而不是往拥有最小磁盘空间的路径新增分区;
num.recovery.threads.per.data.dir
对于如下3种情况,Kafka会启用可配置的线程池来处理日志片段: 1.服务器正常启动,用于打开每个分区的日志片段; 2.服务器崩溃后重启,用于检查和截短每个分区的日志片段; 3.服务器正常关闭,用于关闭日志片段。 默认情况下,log.dirs指定的每一目录都会有一个独立的线程进行处理,如果设置num.recovery.threads.per.data.dir=8,并且log.dirs包含3个目录路径, 那么总共需要24个线程;
num.partition
num.partitions参数指定了新创建的主题将包含多少个分区。如果启用了主题自动创建功能(该功能默认是启用的),主题分区的个数就是该参数指定的值。该参数的默认值是1。要注意,我们可以增加主题分区的个数,但不能减少分区的个数。所以,如果要让一个主题的分区个数少于num.partitions指定的值,需要手动创建该主题;
如何选定num.partitions数量?
- 主题需要达到多大的吞吐量?例如,是100KB/s还是100MB/s;
- 从单个分区读取数据的最大吞吐量是多少?每个分区一般会有一个消费者,如果你知道消费者将数据写入数据库的速度不会超过50MB/s,那么你也该知道,从一个分区读取数据的吞吐量不需要超过50MB/s;
- 可以通过类似的方法估算生产者想单个分区写入数据的吞吐量,不过生产者的速度一般比消费者快的多,所以最好为生产者多估算一些吞吐量;
- 每个broker包含的分区个数、可用的磁盘空间和网络带宽;
- 如果消息是按照不同的键来写入分区的,那么为已有的主题新增分区就会很困难;
- 单个broker对分区的个数是有限制的,因为分区越多,占用的内存越多,完成首领选举需要的时间也越长;
如果你估算出主题的吞吐量和消费者吞吐量,可以用主题吞吐量除以消费者吞吐量算出分区的个数。
也就是说,如果每秒钟要从主题上写入和读取1GB的数据,并且每个消费者每秒钟可以处理50MB的数据,那么至少需要20个分区。
这样就可以让20个消费者同时读取这些分区,从而达到每秒钟1GB的吞吐量。如果不知道这些信息,那么根据经验,把分区的大小限制在25GB以内可以得到比较理想的效果。
配置验证
Kafka提供了两个重要的工具用于验证配置:org.apache.kafka.tools 包里的 VerifiableProducer 和 VerifiableConsumer 这两个类。
我们可以从命令行运行这两个类,或者把它们嵌入到自动化测试框架里。其思想是,VerifiableProducer 生成一系列消息,这些消息包含从1到你指定的某个数字。你可以使用与生产者相同的方式来配置VerifiableProducer,比如配置相同的acks、重试次数和消息生成速度。在运行VerifiableProducer时,它会把每个消息是否成功发送到broker的结果打印出来。VerifiableConsumer 执行的是另一个检查——它读取事件(由VerifiableProducer生成)并按顺序打印出这些事件。它也会打印出已提交的偏移量和再均衡的相关信息。
考虑运行以测试以下场景:
- 首领选举:如果我停掉首领会发生什么事情?生产者和消费者重新恢复正常状态需要多长时间?
- 控制器选举:重启控制器后系统需要多少时间来恢复状态?
- 依次重启:可以依次重启broker而不丢失任何数据吗?
- 不完全首领选举测试:如果依次停止所有副本(确保每个副本都变为不同步的),然后启动一个不同步的broker会发生什么?要怎样恢复正常?这样做是可接受的吗?
kafka-verifiable-producer.sh --help
kafka-verifiable-producer.sh \
--topic hello \
--broker-list 127.0.0.1:9091,127.0.0.1:9092,127.0.0.1:9093 \
--max-messages 100 \
--throughput -1 \
--acks -1 \
--value-prefix 888 \
Kakfa Manager管理后台
CMAK(以前称为Kafka Manager)是由雅虎开发的用于管理 Apache Kafka 群集的工具。
1.配置sbt仓库
进入当前用户目录,配置sbt的Maven仓库:vim ~/.sbt/repositories,使用sbt -v验证
[repositories]
local
aliyun: http://maven.aliyun.com/nexus/content/groups/public/
typesafe: http://repo.typesafe.com/typesafe/ivy-releases/, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly
sonatype-oss-releases
maven-central
sonatype-oss-snapshots
2.安装sbt依赖
./sbt clean dist
命令执行完成后,在 target/universal 目录中会生产一个zip压缩包kafka-manager-1.3.3.7.zip。将压缩包拷贝到要部署的目录下解压
修改bin/kafka-run-class.sh脚本,设置JMX密码文件的位置
# JMX settings
if [ -z "$KAFKA_JMX_OPTS" ]; then
KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.authenticate=true
-Dcom.sun.management.jmxremote.password.file=$base_dir/config/jmxremote.password
-Dcom.sun.management.jmxremote.ssl=false"
fi
最低配置是要用于kafka管理器状态的zookeeper主机。这可以在conf目录下的application.conf文件中找到
./bin/kafka-manager -Dconfig.file=./conf/application.conf -Dhttp.port=9999
Kafka-Manage基于JMX对Kafka进行监控,因此,启用Kafka时设置JMX的端口,通过JMX_PORT环境变量指定
JMX_PORT=8888 kafka-server-start.sh config/server-1.properties
3.启动kafka-manager
nohup /usr/local/kafka-manager/bin/kafka-manager -Dconfig.file=/usr/local/kafka-manager/conf/application.conf -Dhttp.port=9999 >> /data/logskafka/kafka-manager.log 2>&1 &
Kafka Connect工具
--topics-with-overrides
参数可以找出所有包含覆盖配置的主题,它只会列出包含了与集群不一样配置的主题。
--under-replicated-partitions
参数可以列出所有包含不同步副本的分区。使用
--unavailable-partitions
参数可以列出所有没有首领的分区,这些分区已经处于离线状态,对于生产者和消费者来说是不可用的。
kafka-consumer-groups.sh
工具可以用于列出消费者群组。
对于列出的任意群组来说,
使用 --describe代替 --list,并通过 --group指定特定的群组,就可以获取该群组的详细信息。它会列出群组里所有主题的信息和每个分区的偏移量。
Kafka 生产者
发送消息方式
Kafka 生产者架构图
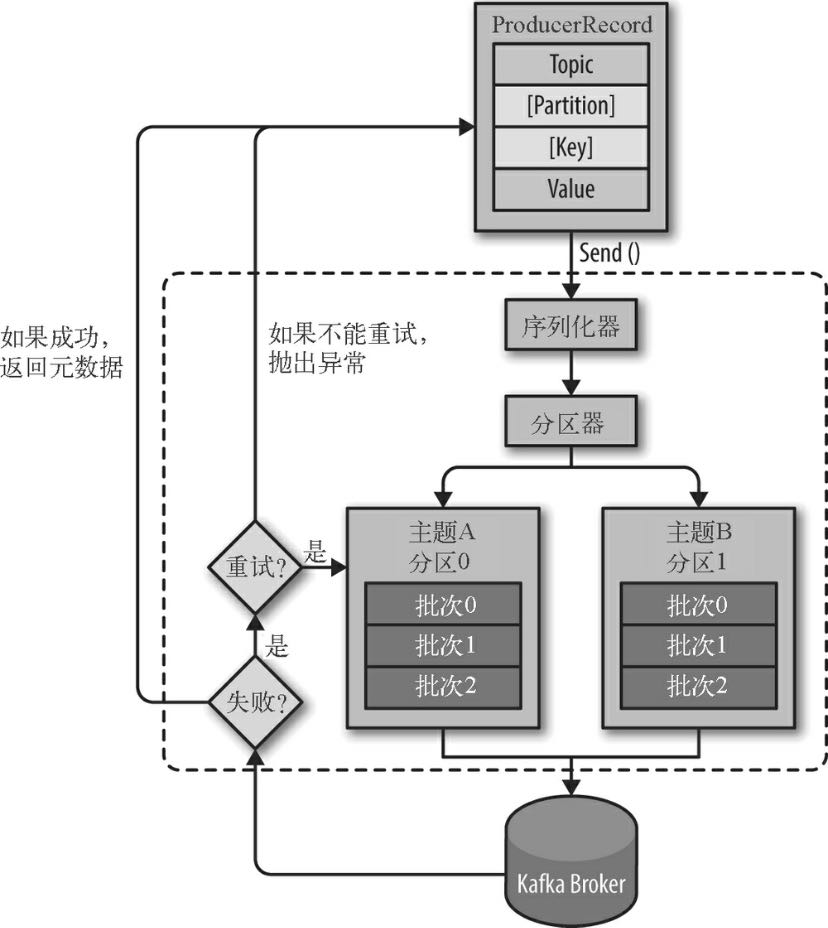
从生产者的架构图里可以看到,消息先是被放进缓冲区,然后使用单独的线程发送到服务器端。
send()方法会返回一个包含 RecordMetadata 的 Future 对象,然后调用 Future 对象的 get() 方法等待 Kafka 响应。如果服务器返回错误,get()方法会抛出异常。
如果没有发生错误,我们会得到一个 RecordMetadata 对象,可以用它获取消息的偏移量。
同步发送消息(是否忽略是否发送成功)
ProducerRecord<String,String> record = newProducerRecord<>("CustomerCountry","PrecisionProducts","France");
try {
producer.send(record); // 忽略消息是否发送成功
producer.send(record).get(); // 同步等待broker响应
} catch(Exceptione) {
e.printStackTrace();
}
异步发送消息
ProducerRecord<String,String> record = newProducerRecord<>("CustomerCountry","BiomedicalMaterials","USA");
producer.send(record,newDemoProducerCallback());
生产者的配置
Kafka生产者一般会发生两类错误:
-
可重试解决错误 这类错误可以通过重发消息来解决,KafkaProducer可以配置成自动重试,如果在多次重试后仍然无法解决问题,应用程序会收到一个重试异常;
-
无法重试解决错误 对于无法重试解决的错误,KafkaProducer不会进行任何重试,直接抛出异常;
Kafka 消费者
首次连接时,可以通过 KafkaConsumer 配置参数里的auto.offset.reset参数决定是从最新的位置(默认)还是从最早的位置开始消费。
默认情况下, enable.auto.commit参数是true,即 KafkaConsumer 客户端会定时 commit offset。
所有要注意的一点是如果poll函数得到ConsumerRecords后如果处理是异步的,则可能出现消费处理还没有完成但是却commit offset了,这时如果进程挂掉则重启后则会发生丢消息的情况。
这里有两种解决方案:
- 是poll后的处理是同步的,这样下一次poll会尝试commit offset,则能保证at least one语义。
- 是关闭
enable.auto.commit, 然后通过KafkaConsumer.commitSync方法来手动commit offset。
max.poll.interval.ms参数用于设置kafka消费者处理一次poll的消费结果的最大时间(默认300s),如果超过了这个时间则consumer被认为挂了会重新rebalance。
不要让消费者的数量超过主题分区的数量,多余的消费者只会被闲置。
Kafka 消息传递保障
Kafka Delivery Guarantee(Kafka消息传递保障),包含以下三种消息传递保障:
At most once(至多一次)消息可能会丢,但绝不会重复传输At least one(至少一次)消息绝不会丢,但可能会重复传输Exactly once(仅且一次)每条消息肯定会被传输一次且仅传输一次,很多时候这是用户所想要的。
Producer Delivery Guarantee (生产者发送消息保障) (Producer->Broker)
当Producer向broker发送消息时,因为Replication的存在,一旦消息被commit就不会丢失。
但是如果Producer发送数据给Broker后,遇到网络问题而造成通信中断,那Producer就无法判断该条消息是否已经commit。
虽然Kafka无法确定网络故障期间发生了什么,但是Producer可以生成一种类似于主键的东西,发生故障时幂等性的重试多次,从而实现Exactly once(仅且一次)的消息发送,但目前此Feature还并未实现。
默认情况下,一条消息从Producer到Broker的传递保障为At least once(至少一次),业务层必须考虑消费服务的幂等性。
可以通过设置 Producer 异步发送实现 At most once。
Consumer Delivery Guarantee (消费者接收消息保障) (Broker->Consumer)
对于Kafka consumer high level API,Consumer从Broker读取消息后,可以选择commit,该操作会在Zookeeper中保存该Consumer在该Partition中读取消息的offset。
当Consumer下一次再读该Partition时,会根据offset从下一条开始读取。如果没有commit,下一次读取的开始位置会跟上一次commit之后的开始位置相同。
可以将Consumer设置为autocommit,即Consumer一旦读到数据立即自动commit。如果只讨论这一读取消息的过程,那Kafka是确保了Exactly once。
但实际使用中应用程序并非在Consumer读取完数据就结束了,而是要进行进一步处理,而处理消息与commit的顺序在很大程度上决定了消费者接收消息传递保障的语义。
-
读完消息先commit再处理消息 这种模式下,如果Consumer在commit后还没来得及处理消息就crash了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息,这就对应于
At most once语义。 -
读完消息先处理消息再commit 这种模式下,如果在处理完消息之后commit之前Consumer crash了,下次重新开始工作时还会处理刚刚未commit的消息,实际上该消息已经被处理过了,这就对应于
At least once语义。 考虑在很多使用场景下,消息都包含唯一标识,所以消息的处理往往具有幂等性,即多次处理这一条消息跟只处理一次是等效的,就可以认为是满足了Exactly once语义。 -
如果一定要做到
Exactly once,就需要协调offset和实际操作的输出经典的做法是引入两阶段提交。如果能让offset和操作输入存在同一个地方,会更简洁和通用。这种方式可能更好,因为许多输出系统可能不支持两阶段提交。比如,Consumer拿到数据后可能把数据放到HDFS,如果把最新的offset和数据本身一起写到HDFS,那就可以保证数据的输出和offset的更新要么都完成,要么都不完成,间接实现Exactly once语义。(目前就high level API而言,offset是存于Zookeeper中的,无法存于HDFS,而low level API的offset是由自己去维护的,可以将之存于HDFS中) 总之,Kafka默认保证At least once,并且允许通过设置Producer异步提交来实现At most once。
通过实现结合具有事务模型或唯一键特性的外部存储系统,Kafka也能够支持实现Exactly once,幸运的是Kafka提供的offset可以很容易的实现这种方式。
Kafka 设计原理
Kafka的设计理念之一就是同时提供离线处理和实时处理。根据这一特性,可以使用Storm这种实时流处理系统对消息进行实时在线处理,同时使用Hadoop这种批处理系统进行离线处理。
Push模式:很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。Push模式的目标是尽可能以最快速度传递消息,但是这样很容易造成Consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。Pull模式:则可以根据Consumer的消费能力以适当的速率消费消息,但是无法保证消息处理的及时性;
Kafka集群
Kafka的消息复制机制只能在单个集群里进行,不能在多个集群之间进行。
Kafka提供了一个叫作 MirrorMaker的工具,可以用它来实现跨集群间的消息复制。
MirrorMaker的核心组件包含了一个生产者和一个消费者,两者之间通过一个队列相连。
消息主题(Topic)
Topic是发布消息/订阅消息所属类别的抽象。
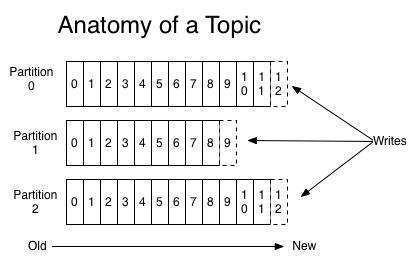
分区日志(Partition Log)
针对每一个Topic,Kafka集群会维护一组物理真是存在的分区日志。
每个分区日志都是一个有序且不可变的消息序列,消息不断追加到结构化的分区日志中。
分区日志为每个消息都分配了一个称为偏移的顺序ID号,它唯一地标识了分区日志中的每个消息。
无论分区日志中的消息是否被消费过,Kafka集群都会持久保存所有的分区日志,并按照配置的保留期删除历史分区日志中的消息;
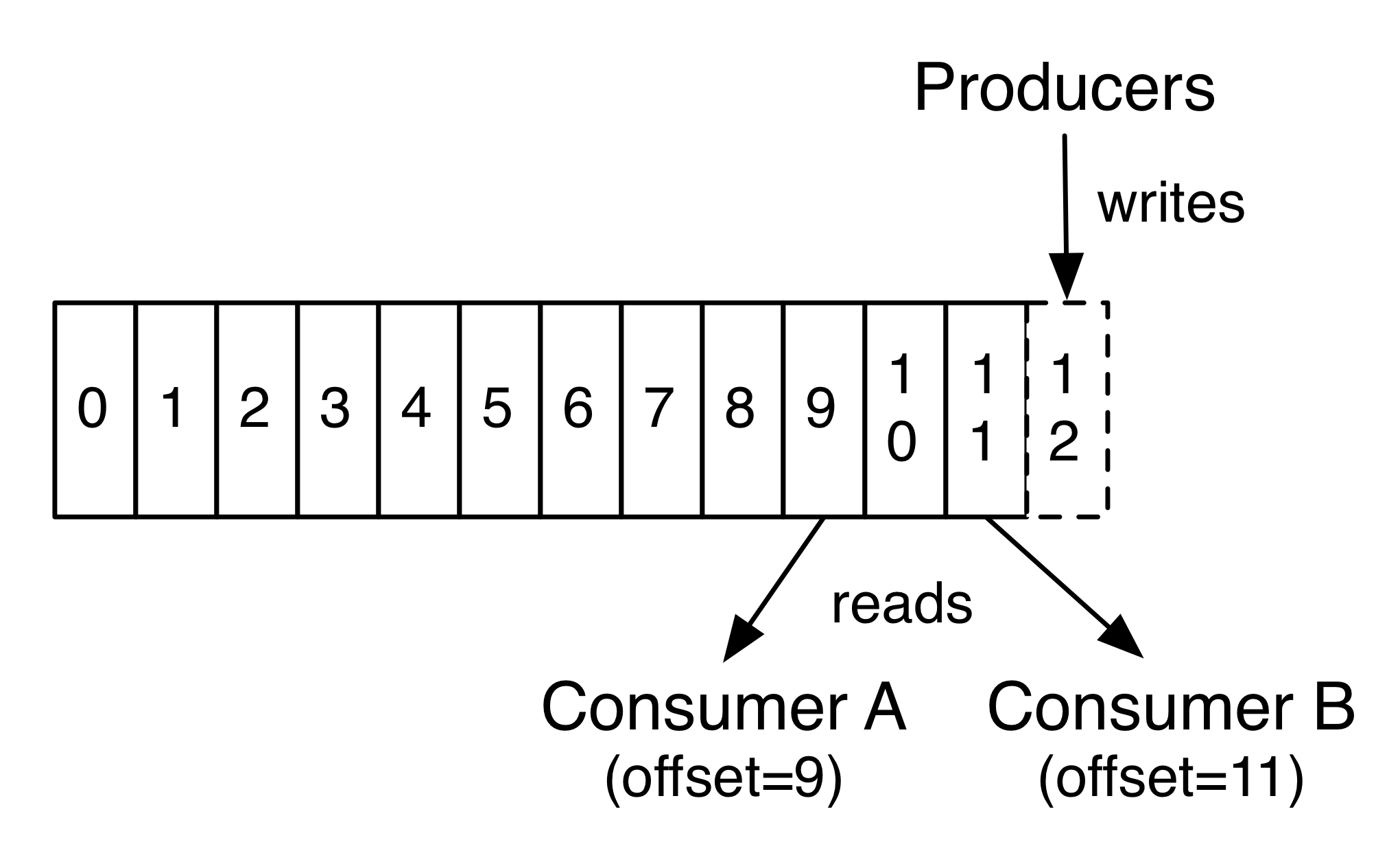
实际上,每个消费者保留的唯一元数据就是已经消费过的消息在分区日志中的偏移量。 这种偏移由消费者控制:通常消费者在读取记录时会线性地提高其偏移量,但事实上,由于该位置由消费者控制,因此它可以按照自己喜欢的任何顺序消费记录。 例如,消费者可以将偏移量重置为较旧的偏移量来重新处理过去的数据,或者跳到最近的记录并从当前开始消费。
分区日志分布式
每个Topic对应的一组分区日志,分区日志分布在Kafka集群中不同服务器的Broker上,同一个Topic的分区日志所在的Broker中,都有一个Broker充当领导者,其他Broker充当追随者。领导者处理对应分区的所有读取和写入请求,而追随者被动地复制领导者,如果领导者失败,其中一个追随者将自动成为新的领导者。 每个服务器都充当其某些分区的领导者和其他服务器的追随者,因此负载在群集中得到很好的平衡。
对于具有复制因子N的主题,我们将容忍最多N-1个服务器故障,而不会丢失任何提交到日志的记录。
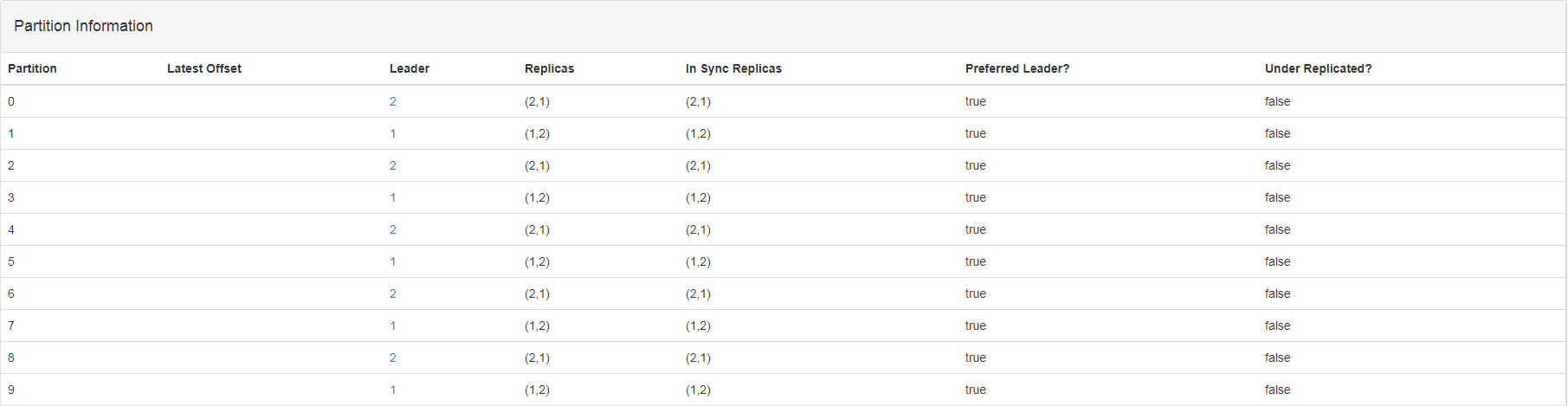
通过命令创建一个名为test的Topic,设置Topic包含10个分区日志,并且为每个分区日志创建一个副本:
kafka-topics.sh --create --zookeeper localhost:2181 --partitions 10 --replication-factor 2 --topic test
通过Kafka-Manager观察集群中的Broker数量为2(即集群中有2台服务器:Broker-1、Broker-2) Broker-1包含10个分区日志,5个分区日志的Leader(1,3,5,7,9),5个分区日志的Follower(0,2,4,6,8) Broker-2包含10个分区日志,5个分区日志的Leader(0,2,4,6,8),5个分区日志的Follower(1,3,5,7,9) 假设写入Partition-3,那么客户端会将消息会被发送给Broker-1,由Broker-1将消息追加到分区日志3中,然后,Broker-2会将数据复制到自己的副本分区日志3中。 即时Broker-1所在的服务宕机,Broker-2会从5个分区日志(1,3,5,7,9)的Follower变为新的Leader,接收对应分区日志的所有读写请求;

分区日志消息结构
分区日志中的每一条消息由Magic Number(魔数:1 bytes)、CRC(循环冗余校验码:4 bytes)、Payload(有效载荷构成:N bytes),消息总长度为5+N字节。
分区日志删除策略
Kafka提供两种策略删除旧数据:
- 基于时间的策略
- 基于Partition文件大小的策略
# The minimum age of a log file to be eligible for deletion
log.retention.hours=168
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according to the retention policies
log.retention.check.interval.ms=300000
# If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction.
log.cleaner.enable=false
Kafka 集群监控
生产者监控
Kafka的Java客户端包含了JMX度量指标,这些指标可以用于监控客户端的状态和事件。 对于生产者来说,最重要的两个可靠性指标是消息的error-rate和retry-rate,如果这两个指标上升,说明系统出现了问题。
除此以外,还要监控生产者日志——发送消息的错误日志被设为WARN级别,可以在Goterrorproduceresponsewithcorrelationid5689ontopic-partition[topic-1,3],retrying(twoattemptsleft).Error:...中找到它们。如果你看到消息剩余的重试次数为0,说明生产者已经没有多余的重试机会。
消费者监控
对于消费者来说,最重要的指标是consumer-lag,该指标表明了消费者的处理速度与最近提交到分区里的偏移量之间还有多少差距。理想情况下,该指标总是为0,消费者总能读到最新的消息。不过在实际当中,因为poll()方法会返回很多消息,消费者在获取更多数据之前需要花一些时间来处理它们,所以该指标会有些波动。关键是要确保消费者最终会赶上去,而不是越落越远。因为该指标会正常波动,所以在告警系统里配置该指标有一定难度。
Burrow 是 LinkedIn 公司开发的一个 Apache Kafka consumer-lag 检测工具,它将consumer lag检查作为服务提供,无需指定阈值。Burrow 监控所有消费者已提交的偏移量并且按需计算那些消费者的状态。提供HTTP endpoint以根据需要请求状态,并提供其他Kafka集群信息。还有可配置的通知程序,可以通过电子邮件或HTTP呼叫将状态发送到其他服务。
有两个比较有用但在操作系统里难以收集到的属性:
- MaxFileDescriptorCount 展示JVM能够打开的文件描述符(FD)数量的最大值,
- OpenFileDescriptorCount 展示目前已经打开的文件描述符数量。
每个日志片段和网络连接都会打开一个文件描述符,所以它们的数量增长得很快。如果网络连接不能被正常关闭,那么broker很快就会把文件描述符用完。
JVM监控
如果JRE使用了Java 8,并使用了G1垃圾回收器,那么需要监控的MBean G1垃圾回收器度量指标名字 JMXMBeanFullGCcyclesjava.lang:type=GarbageCollector,name=G1OldGenerationYongGCcyclesjava.lang:type=GarbageCollector,name=G1YoungGeneration在垃圾回收语义里,Old和Full的意思是一样的。我们需要监控这两个指标的CollectionCount和CollectionTime属性。 CollectionCount表示从JVM启动开始算起的垃圾回收次数,