CPU架构
CPU缓存
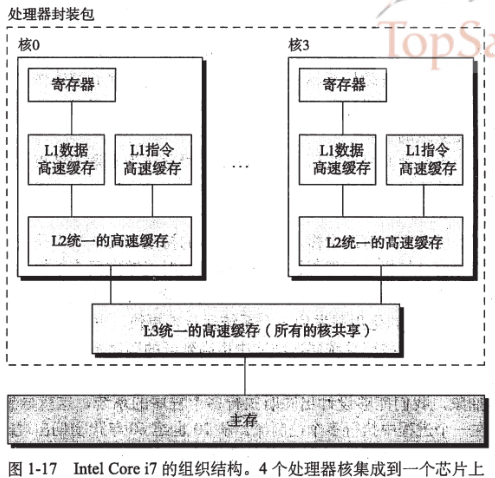
多核处理器:将多个CPU(称为”核”)集成到一个集成电路芯片上。
Intel Core i5-2520M (PGA) specifications
Level 1 cache size
- 2 x 32 KB 8-way set associative instruction caches
- 2 x 32 KB 8-way set associative data caches
Level 2 cache size
- 2 x 256 KB 8-way set associative caches
Level 3 cache size
- 3 MB 12-way set associative shared cache
L1 Cache
在现代微处理器中,如Intel Core i5-2530M型号的双核CPU,缓存配置为:2 x (32KB + 32KB + 256KB) + 3M L1 cache被分割为两个大小相同的缓存,一个用于缓存数据(32KB),一个用于缓存微处理器指令(32KB)。
L2 Cache
Level2 cache,又被称为secondary cache,用于存储最近访问的信息。其目的在于可以减少访问相同数据的时间。在具有数据预抓去的现在微处理器中,Level2 cache用于缓存将要从系统内存中获取的程序指令与数据。注意Level2 cache是CPU的二级缓存,没有Level1 cache的速度快,尽管Level2 cache的容量更大。Level2 cache通常 作为一个统一的整体,既用于存储程序指令,又用于存储程序数据。Level2 cache通常被简称为L2 cache。
L2 cache可能存在于以下位置:
- on the processor core - integrated or on-die cache.
- in the same package/cartridge as the processor, but separate from the processor core - backside cache.
- separate from the core and processor package. In this case L2 cache memory is usually located on the motherboard.
L3 Cache
L3 Cache缓存被所有核心共享,大小为3M,速度相比而言也是最慢。
CPU架构
# 查看CPU的架构
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Stepping: 1
CPU MHz: 2097.440
BogoMIPS: 4194.70
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 20480K
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31
SMP架构
SMP(Symmetric Multiprocessing)对称多处理器。顾名思义, 在SMP中所有的处理器都是对等的, 它们通过总线连接共享同一块物理内存。
NMUA架构
- 单核CPU -> FSB总线 -> 内存控制器(北桥) -> 内存1/内存2/…/内存N
- 多核CPU1/CPU2/…/CPUN -> FSB总线 -> 内存控制器(北桥) -> 内存1/内存2/…/内存N
刚开始核不多的时候,FSB总线勉强还可以支撑。但是随着CPU内核越来越多,所有的数据IO都通过一条FSB总线和内存交换数据,这条FSB就成为了整个计算机系统的瓶颈。
为了解决这个问题,CPU的设计者们引入了QPI总线,相应的CPU的结构就叫NMUA架构;
内存1/内存2 <- CPU1内存控制器 <– QPI总线 –> CPU2内存控制器 -> 内存3/内存4
NUMA陷阱
NUMA陷阱指的是引入QPI总线后,在计算机系统里可能会存在的一个坑。大致的意思就是如果你的机器打开了NUMA,那么你的内存即使在充足的情况下,也会使用磁盘上的swap,导致性能低下。
原因就是NUMA为了高效,会仅仅只从你的当前node里分配内存,只要当前node里用光了(即使其它node还有),也仍然会启用硬盘swap。
# 查看服务器NUMA状态(机器有两个内存区域(zone):node0和node1,分别有16个核心,各有32GB的内存)
$ numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30
node 0 size: 32546 MB
node 0 free: 13991 MB
node 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31
node 1 size: 32768 MB
node 1 free: 14528 MB
node distances:
node 0 1
0: 10 21
1: 21 10
# 查看内存区域(zone)内部的内存耗尽时的回收策略(机器的zone_reclaim_mode=1,内存区域内部的内存耗尽后,只会在本地节点回收内存)
# 0 关闭zone_reclaim模式,可以从其他zone或NUMA节点回收内存
# 1 打开zone_reclaim模式,这样内存回收只会发生在本地节点内
# 2 在本地回收内存时,可以将cache中的脏数据写回硬盘,以回收内存
# 4 在本地回收内存时,表示可以用Swap方式回收内存
$ cat /proc/sys/vm/zone_reclaim_mode
1
# 查看内存区域的内存使用情况
$ cat /proc/zoneinfo | grep 'Node \<[[:digit:]]\{1,2\}\>, zone Normal' -A 1 --color
Node 0, zone Normal
pages free 3329247
--
Node 1, zone Normal
pages free 3725673
在zone_reclaim_mode为1的情况下,Redis是平均在两个node里申请节点的,并没有固定在某一个CPU里。
如果不绑定亲和性的话,分配内存是当进程在哪个node上的CPU发起内存申请,就优先在哪个node里分配内存。
之所以是平均分配在两个node里,是因为redis-server进程实验中经常会进入主动睡眠状态,醒来后可能CPU就换了。所以基本上,最后看起来内存是平均分配的。
# 查看上下文切换(CPU进行了500万次的上下文切换,用top命令看到cpu也是在node0和node1跳来跳去)
$ grep ctxt /proc/8356/status
voluntary_ctxt_switches: 5259503
nonvoluntary_ctxt_switches: 1449
# 绑定CPU和内存的亲和性
$ numactl --cpunodebind=0 --membind=0 ./redis-server ./redis.conf